Deepseek OCR
DeepSeek เปิดตัวโมเดล AI ใหม่ "แปลงข้อความเป็นภาพ" บีบอัดบริบทได้ถึง 10 เท่า

ถ้าพูดถึงปัญหาใหญ่ของ AI อย่าง ChatGPT หรือ Claude ตัวหนึ่งที่หลายคนอาจไม่รู้คือ เวลาต้องจำข้อมูลเยอะ ๆ มันกินหน่วยความจำและเวลาประมวลผลมหาศาล วันนี้ DeepSeek (สตาร์ตอัป AI จากจีน) มีไอเดียบ้า ๆ ที่อาจเปลี่ยนเกมได้เลย — แทนที่จะเก็บข้อความยาว ๆ ให้เปลี่ยนเป็นภาพแทน!
ทำงานยังไง?
โมเดลรุ่นใหม่ของ DeepSeek ใช้เทคนิคที่เรียกว่า "Text-to-Image Compression" หรือ Visual Token Compression (VTC) ซึ่งทำงานตรงข้ามกับ OCR ทั่วไปเลย
แทนที่จะ: อ่านภาพ → ถอดเป็นข้อความ (แบบ OCR)
DeepSeek ทำแบบนี้: เอาข้อความยาว ๆ → แปลงเป็นภาพที่เข้ารหัสความหมาย → ส่งให้ AI อ่านต่อ
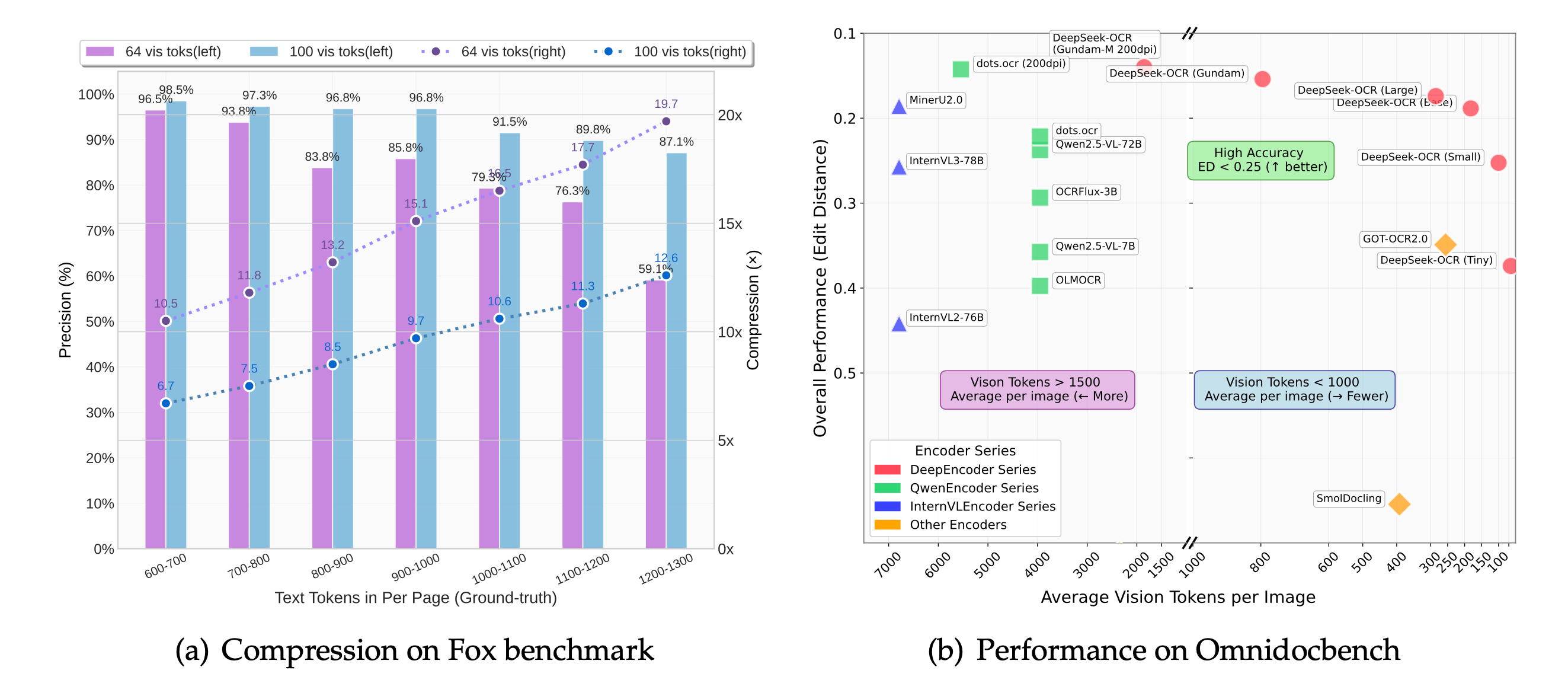
ผลลัพธ์ที่ได้: ลดจำนวน token ได้ 7-20 เท่า ความแม่นยำในการถอดกลับยังคงอยู่ที่ประมาณ 97%
(ง่าย ๆ คือ AI จำข้อมูลได้เยอะขึ้นมาก แต่กินทรัพยากรน้อยลง)
ทำไมถึงสำคัญ?
1.) แก้ปัญหา "context window" ที่มีมานาน ยิ่ง AI ต้องจำข้อมูลเยอะเท่าไร (เช่น อ่านเอกสารยาว 100 หน้า) ก็ยิ่งต้องใช้หน่วยความจำ (VRAM) และเวลาในการประมวลผลมากขึ้น → ต้นทุนพุ่ง การเปลี่ยนข้อความเป็นภาพทำให้ "อ่านข้อมูลเดิมซ้ำ" ถูกลงมหาศาล เพราะไม่ต้องเก็บข้อความทั้งหมด แต่เก็บเป็น latent image (ภาพที่เข้ารหัสความหมาย) แทน
2.) เปิดทางสู่ LLM ที่ใช้งานได้บนเครื่องทั่วไป ถ้าโมเดลใช้หน่วยความจำน้อยลง → AI ขนาดใหญ่อาจรันได้บนคอมหรือมือถือเราโดยตรง ไม่ต้องพึ่ง cloud
3.) ท้าทายโครงสร้างเดิมของ Transformer การใช้ token (หน่วยคำ) เป็นพื้นฐานของ AI มาตั้งแต่ปี 2017 แต่ DeepSeek บอกว่า "ภาพอาจเก็บความหมายได้ดีกว่า" → ถ้าจริง อาจต้องออกแบบ AI รุ่นใหม่ใหม่เลย
ข้อสงสัย
แม้จะฟังดูดี แต่ก็มีนักวิจัยหลายคนตั้งคำถามว่า:
การแปลงเป็นภาพอาจทำให้ AI ไตร่ตรองและคิดเชิงตรรกะได้แย่ลง เพราะไม่ได้เห็นลำดับคำโดยตรงอีกต่อไป ความแม่นยำ 97% ดูดี แต่ใน 3% ที่เหลืออาจมีข้อมูลสำคัญหายไปได้
(ก็เหมือนการจดโน้ตด้วยภาพแทนตัวหนังสือ — เร็วและกระชับ แต่อาจพลาดรายละเอียดบางอย่าง)
มองยังไง?
โดยส่วนตัวผมคิดว่านี่คือหนึ่งในไอเดียที่ "บ้าพอที่จะได้ผล" เพราะมันท้าทายสิ่งที่เราคิดว่าเป็นพื้นฐานของ AI มาตลอด
ถ้า DeepSeek พิสูจน์ได้ว่าเทคนิคนี้ใช้งานจริงได้และไม่ทำให้คุณภาพตกมากจนเกินไป มันอาจเป็น "จุดเปลี่ยนครั้งใหญ่" ในวงการ LLM โดยเฉพาะด้าน memory efficiency และที่สำคัญ — DeepSeek เปิดโค้ดทั้งหมดให้ฟรีบน GitHub ซึ่งหมายความว่าชุมชนนักวิจัยทั่วโลกสามารถนำไปพัฒนาต่อได้เลย
สรุป
DeepSeek เปิดตัวโมเดล AI ใหม่ที่ แปลงข้อความเป็นภาพเพื่อบีบอัดบริบท ได้มากกว่า 10 เท่า โดยยังคงความแม่นยำไว้ได้ถึง 97%
ถ้าเทคนิคนี้ได้รับการพิสูจน์และพัฒนาต่อ มันอาจนำไปสู่ AI รุ่นใหม่ที่มองเห็นความหมายผ่านภาพแทนคำ และทำให้ LLM ขนาดใหญ่ใช้งานได้บนเครื่องทั่วไปในอนาคต
ติดตามกันต่อนะครับว่าเทคโนโลยีนี่จะพัฒนาไปในทิศทางไหน — ถ้าผิดพลาดตรงไหนคอมเม้นบอกได้เลยครับ!
แหล่งอ้างอิง
VentureBeat - DeepSeek drops open-source model (October 2025)
VentureBeatGitHub DeepSeek Project Repository